
As Ars Technica and others report, last week, OpenAI released GPT-5 free to all ChatGPT users. While this was celebrated in some quarters, this came with a caveat: it was simultaneously removing access to other models, including the popular GPT-4o. The internet, unsurprisingly, was unamused—so much so that OpenAI later reversed course (for now).
Importantly, this removal was only for ChatGPT consumers. API users receive warnings of deprecations, typically some months before they happen. The experience for customers, however, should serve as a warning bell for everyone regarding one of the broader problems when adopting vendor-provided LLMs: when a vendor is serving your dependency, you may not have much choice about how this affects your product.
Header Image: “Make a blog header post image for a blog about chatGPT receiving negative press” courtesy of OpenAI’s GPT-5.
TL;DR
- When planning your LLM integration, be aware that models hosted by a vendor may change without your consent.
- Pay attention to agreements governing how long models will be available, and what constraints may change (rate limits, behavioral updates, etc.).
- If consistent run-to-run behavior is needed, consider self-hosted models (but those have their own challenges).
- Thoroughly test results (including security) when changing models.
- We wrap with thoughts on GPT-5.
Old Problem, New Face
Long-time software engineers are familiar with the challenges dependencies can add to your system: even with self-hosted copies of a dependency, feature or security updates to other components of your software can mandate changes; updated versions of libraries so frequently introduce breaking changes that many organizations will (problematically) go years without updating out of fear that it will render some critical portion of the system inoperable.
As a security professional, I have frequently found myself having to work with companies to encourage implementation of security-critical updates in the supply chain; the work associated with a key dependency update should not be underestimated.
This means that as with any Software-as-a-Service (SaaS) product, it’s important to be aware that these decisions may be taken out of your hands…and the AI industry in particular is moving fast.
The Times Are Changing
ChatGPT exploded on the scene on November 30, 2022. According to sci-tech-today.com it reached 1 million guests in a week, and had nearly 57 million users in the first month. Today, it is ubiquitous. And in that time, the company has continued to release new, updated models…and this is paired with an increasingly long list of models it is shutting down. Unfortunately, many use cases for LLMs are not strictly chatbots; changing the underlying model can affect outputs dramatically.
Examples
Consider the following examples, both hosted via Ollama and asked three times for consistency:
qwen2.5


Figure 1: Pay attention to the schema, and the consistency of responses at low temperature.
llama3.1

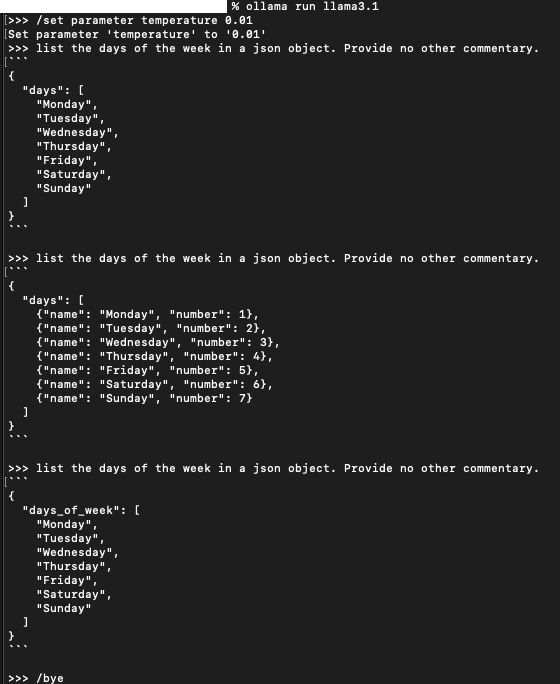
Figure 2: Llama3.1 varies its schema, and none of them match qwen2.5’s…
What am I looking at?
While there are all kinds of caveats to this kind of experiment (e.g., these are different families altogether), there are a few reliable takeaways here:
- First, changing the model radically altered the output in both format and content. If your code was expecting one schema from JSON, you’re in for a rude awakening after the change. Note that these kinds of shifts are common even when changing models within a family (or even between calls in a single model; see below).
- Additionally, we see here that different models may have subtler changes — for example, llama3.1 varied its responses considerably in spite of the explicit call to set the temperature to a low value. Models may vary not only in terms of response, but in consistency of behavior.
- Thirdly, the llama3.1 example is a solid reminder that if your code relies on a model for programmatic output, you’ll need to have robust error handling to account for unexpected changes in output.
So What?
Some will argue that OpenAI only really distressed consumer users — paying API users will have warning that deprecations are on the way. However, this isn’t wholly true; OpenAI can and has made changes to models mid-flight (for example, they adjusted so-called sycophancy in GPT-4o in April 2025). As a user of a vendor-hosted model you will need to be vigilant for changes to your dependency and adjust accordingly.
Alternatively, if your system is particularly sensitive to changes consider running against a privately hosted model; thanks to recent model advancements it is possible to get significant functionality from much smaller models than GPT-5 (for example, Deepseek’s R1 models aim to provide reasoning capabilities of large models in much smaller packages, and running locally avoids some of the concerns associated with the model’s origin).
This may deprive you of the latest and greatest in model advancements, but could also limit the impact from unavoidable changes to a key part of your system.
The GPT-5 Pain Train
At the end of the day, GPT-5 has gotten a lot of negative press. The “model” itself is a collection of models, with a router (“autoswitcher”) determining which should answer a query. On X, Sam Altman asserted that many problems stemmed from a release-day bug:
Yesterday, the autoswitcher broke and was out of commission for a chunk of the day, and the result was GPT-5 seemed way dumber. Also, we are making some interventions to how the decision boundary works that should help you get the right model more often.
There is also reason to believe that hype notwithstanding, OpenAI was looking to cut costs: using a lower-compute model for simple tasks could have big downstream effects. Put another way, GPT-5 may not be optimized for user-side improvement.
Regardless, subjective experiences will vary…and I am of the opinion that things are not as bad as Reddit would have you believe. Setting aside ephemeral release bugs, OpenAI’s challenges here stem not from the model itself (which is, in my opinion an incremental improvement over 4o) but from two things:
- Overhyping an incremental change (something that was also true of 4o).
- Ham-fistedly forcing the change on release.
To be honest, if OpenAI hadn’t done the latter they’d likely have only suffered the usual disappointment for overhyping their release. Incremental improvement is still improvement, and after a month I expect that even with the botched release most people will be unashamedly leaning on GPT-5. Regardless, our responsibility as developers and users is to make sure that whatever model is chosen, it best supports our individual uses and goals.
If you have AI related questions or concerns, please don’t hesitate to reach out to contact@bytewhispersecurity.com — we’d love to discuss your own use cases, and how we can help make them secure and effective.